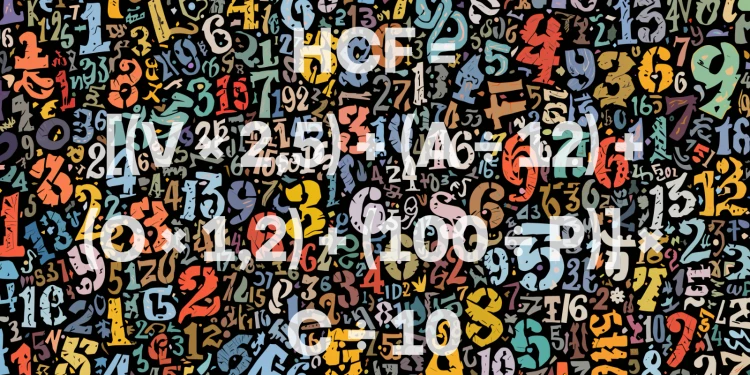
Bildnachweis: –
Die Messung des Vergessens
Wer eine Bibliografie pflegt, kennt das Dilemma. Einerseits will man nichts behaupten, was sich nicht belegen lässt. Andererseits juckt es einen in den Fingern, aus den Daten mehr zu machen als bloße Auflistungen. Die Zahlen sind da, sie liegen in der Datenbank wie schlummernde Schätze – und irgendwann stellt sich die Frage der Fragen: Was erzählen uns die Datensätze eigentlich?
Bei der Arbeit an der deutschen Simenon-Bibliografie, die in diesem Jahr gut zweiundzwanzig Jahre auf den Buckel hat, haben sich zwei Listen geradezu aufgedrängt: eine Hitparade der meistgedruckten Romane und ein Verzeichnis der Vergessenen. Die erste war schnell erstellt – man zählt die Ausgaben und sortiert absteigend. Simple Mathematik, unanfechtbare Ergebnisse. Aber die zweite Liste? Sie verlangte nach mehr. Sie verlangte nach dem, was die Wissenschaft eine »Metrik« nennt. Außerdem ist es die Liste, an das Herz der Sammler:innen und Simenon-Liebhaber:innen hängt. In ihr finden sich die Träume wieder, manchmal auch feuchte, die schlaflose Nächte bereiten können.
Die Favoriten: Demokratie der Neuauflagen
Beginnen wir mit dem Einfachen. Die Frage »Welche Simenon-Romane sind in Deutschland am häufigsten erschienen?« lässt sich mit einer schlichten SQL-Abfrage* beantworten:
COUNT(Ausgaben) → Sortierung → RanglisteDas Ergebnis ist unbestechlich. Keine Interpretation, keine Gewichtung, keine Willkür. Der Computer zählt, der Mensch staunt. Ob ein Roman 1952 oder 2022 erschienen ist, spielt keine Rolle. Jede Ausgabe ist gleich viel wert – eine Art literarischer Egalitarismus. Warum diese Stärken bei den Romanen, die in den 1950er-Jahren erschienen sind. Darauf gibt es Antworten, die nicht unmittelbar in den Zahlen zu finden sind. Aber in den Zahlen manifestieren sich Vorlieben, insbesondere die Vorliebe für Maigret. Die, da muss man ehrlich sein, nicht überraschend ist.
Das Schöne an dieser Liste: Sie überrascht bisweilen. Nicht nur die Maigrets haben es in die Liste geschafft, nicht immer die bekannten Titel. Manchmal schiebt sich ein vermeintlich »kleiner« Roman nach vorn, getragen von Taschenbuch-Nachdrucken aus den Siebzigern oder einer besonders aktiven Verlagspolitik oder der Liebhaberei eines Verlegers. (Gern hätte ich auch geschrieben »Verlegerin«, aber zumindest im deutschsprachigen Bereich hat sich noch keine Dame für diese Aufgabe gefunden.)
Die Hitparade der Favoriten ist, bei aller Schlichtheit, ein ehrliches Dokument der deutschen Simenon-Rezeption. Sie zeigt, was die Verlage gedruckt haben – und die druckten nicht, was die Kritik schätzte, sondern die Masse der Leser:innen mochte. Das ist ein Unterschied.
Die Vergessenen: Auf der Suche nach dem perfekten Indikator
Komplizierter wird es bei den Vergessenen. Ab wann gilt ein Roman als vergessen? Ist ein Buch, das seit fünfundzwanzig Jahren nicht mehr erschienen ist, vergessener als eines, das seit 20 Jahren wartet? Was, wenn der eine Titel ursprünglich zehn Auflagen erlebte, das andere nur zwei? Zählt es, wie lange ein Werk überhaupt im Handel war? Und sollte man das Alter des Werks berücksichtigen?
Die einfache Lösung – Jahre seit letzter Ausgabe – schien einfach unbefriedigend. Sie behandelt alle Romane gleich, obwohl die Geschichten der Bücher so unterschiedlich sind. Ein Roman, der 1960 einmal erschien und seither nie wieder, ist anders vergessen als einer, der zwanzig Auflagen erlebte und dann plötzlich verschwand.
Um hier eine Gerechtigkeit und Anerkennung herzustellen, brauchte eine Formel. Es brauchte den Hahn-Claude-Faktor.
Der Hahn-Claude-Faktor (HCF): Anatomie einer Metrik
Der Name ist vollkommen willkürlich gewählt als wäre er von unseren Katzen ausgeknobelt worden und soll dem Ganzen einen wissenschaftlichen Anstrich geben, wie er in der quantitativen Literaturwissenschaft gern gesehen wird. Wir wollen nicht verhehlen, dass die Freude über die Etablierung der der Formel unserem Wirken eine ganz neue Bedeutung geben würde.
Die Formel selbst entstand in nächtlichen Sitzungen am Bildschirm, unter Zuhilfenahme einer KI, die sich vermutlich insgeheim über den Auftrag amüsierte. Denn hier soll nicht verhehlt werden: Mit Büchern kennen wir uns aus, die Mathematik und das Rechnen überlassen wir anderen. (Das ist auch der Grund, warum hier keine Verlagskaufleute das Sagen haben – die können ja rechnen.) Hier haben wir die Formel:
HCF = [(V × 2,5) + (A ÷ 12) + (O × 1,2) + (100 ÷ P)] × C ÷ 10
Und hier wird es nüchtern, weil wie soll man die Bestandteile einer Formel unterhaltsam erklären?
- V = Vergessens-Jahre (seit letzter Ausgabe)
- A = Werk-Alter (aktuelles Jahr minus Entstehungsjahr)
- O = Anzahl der Ausgaben (gedeckelt bei 10)
- P = Popularitätsspanne (letzte Ausgabe minus erste Ausgabe plus 1)
- C = Chaos-Faktor (Datenbank-ID modulo 3, plus 1)
Das Ergebnis wird in Kategorien eingeteilt:
- Unter 20: »Hoffnungsschimmer«
- 20–40: »Kritischer Zustand«
- 40–60: »Akute Vergessensgefahr«
- 60–80: »Literarischer Notfall«
- Über 80: »Katastrophal verloren«
Die Verteidigung: Warum diese Formel eine Seele hat
Betrachten wir die einzelnen Komponenten:
Die Vergessens-Jahre (V) bilden den Kern. Sie werden mit dem Faktor 2,5 multipliziert und dominieren damit das Ergebnis – zu Recht. Denn letztlich ist es genau das, was wir messen wollen: Wie lange wurde ein Werk nicht mehr aufgelegt?
Das Werk-Alter (A) dividiert durch 12 fügt eine Nuance hinzu. Ältere Werke haben – bei gleicher Vergessensdauer – einen höheren HCF. Das erscheint zunächst ungerecht: Sollte ein Roman von 1932 nicht mehr Zeit bekommen haben, vergessen zu werden? Aber die Logik ist eine andere: Je älter ein Werk, desto mehr hätte es eigentlich die Chance gehabt, kanonisiert zu werden. Dass es stattdessen vergessen ist, wiegt schwerer. Außerdem sollten wir uns gerade bei dieser Formel, die für den Simenon-Kanon entwickelt worden ist, fragen: Warum sollte es denn ausgerechnet hier gerecht zugehen? Hier spielt auf jeden Fall Schicksal eine Rolle.
Die Ausgaben-Anzahl (O) ist der eigentlich perfide Teil. Multipliziert mit 1,2 erhöht sie den HCF – mehr Ausgaben bedeuten: mehr vergessen. Das klingt paradox, ist aber nachvollziehbar: Ein Roman, der zehnmal erschien und dann verschwand, ist ein tragischerer Fall als einer, der nur einmal gedruckt wurde. Die erste Geschichte ist ein Aufstieg und Fall, die zweite möglicherweise nur ein Übersetzungszufall.
Die Popularitätsspanne (P) im Nenner belohnt Langlebigkeit. Wenn ein Werk über dreißig Jahre hinweg immer wieder erschien, sinkt der HCF – das Vergessen ist weniger dramatisch, weil das Buch seine Zeit hatte. War ein Roman jedoch nur fünf Jahre »aktuell«, steigt der Faktor: Die kurze Blüte macht das Vergessen rätselhafter.
Der Chaos-Faktor (C) schließlich ist das, was die Statistiker ein »Rauschen« nennen würden. Die Datenbank-ID modulo 3 ergibt Werte zwischen 1 und 3 – eine quasi-zufällige Variation, die verhindert, dass zwei ansonsten identische Fälle exakt denselben HCF erhalten. Man könnte das auch »wissenschaftliche Demut« nennen: Die Formel gibt nicht vor, exakter zu sein, als sie ist.
Die Kritik: Was der HCF nicht kann
Manche werden sagen, der Hahn-Claude-Faktor ist kein seriöses Instrument der Literaturwissenschaft. Wir ahnen welche Einwände kommen werden und sind gewappnet:
Die Willkür der Gewichtungen: Warum 2,5 für die Vergessens-Jahre? Warum nicht 2,3 oder 2,7? Die Faktoren wurden nach Augenmaß gewählt – sie »funktionieren« im Sinne einer plausiblen Verteilung, aber sie sind nicht empirisch hergeleitet.
Die Deckelung der Ausgaben: Bei zehn ist Schluss. Das bedeutet, dass ein Roman mit 15 Ausgaben genauso behandelt wird wie einer mit 10. Die Entscheidung ist praktisch begründet – irgendwann macht »mehr« keinen Unterschied mehr –, aber sie ist eben auch: eine Entscheidung.
Der Chaos-Faktor: Dass die Datenbank-ID die Berechnung beeinflusst, ist natürlich absurd. Die ID ist ein technisches Artefakt, sie sagt nichts über das Werk aus. Aber genau das ist der Punkt: Der HCF will gar nicht objektiv sein. Er will eine Annäherung liefern, keine Wahrheit.
Die fehlenden Dimensionen: Übersetzungsqualität, Verfügbarkeit in Bibliotheken, Sekundärliteratur, Erwähnungen in der Presse – all das fließt nicht ein. Der HCF kennt nur, was die Datenbank kennt: Ausgaben, Jahre, Verlage. Waren Verlage zu faul sich bei der Deutschen Bibliothek zu melden, dann hat das zur Konsequenz, dass sie hier vielleicht nicht erscheinen oder nur mit sehr vagen Werten. Die wiederum die Qualität des Ergebnisses der wunderschönen Formel stören.
Schlussbemerkung: Über den Nutzen von sowas
Der Hahn-Claude-Faktor ist ein Spiel. Er tut so, als wäre er Wissenschaft, und genau darin liegt sein Wert. Denn indem er eine scheinbar objektive Zahl vorgaukelt, zwingt er zur Frage: Was wollen wir eigentlich messen?
Vergessen ist kein binärer Zustand. Es gibt Grade des Vergessens, Schichten, Nuancen. Ein Roman kann bei Sammlern bekannt und beim breiten Publikum vergessen sein. Er kann in Frankreich kanonisch und in Deutschland unbekannt sein. Er kann von der Kritik geschätzt und von den Verlagen ignoriert werden.
Der HCF misst nichts davon. Er misst nur, was sich in einer Datenbank abbilden lässt – und er tut es auf eine Weise, die nicht ganz ernst gemeint ist. Das ist seine größte Stärke: Er macht auf das Problem aufmerksam, ohne so zu tun, als hätte er die Lösung. Denn die Entscheidung was veröffentlicht wird, wird in den Verlagen von Verlegern und Lektoren getroffen. Die schauen nach der Beliebtheit und nach Verkaufszahlen. Dabei – und da sind wir wieder am Anfang dieses Abschnitts – werden Werke aus dem Spiel genommen und das sind die, die sich in dieser Liste wiederfinden.
Und der Faktor ist ja nur eine Zahl, die absolute Anzahl der Jahre des Nichterscheinens die lügt auf keinen Fall.
Disclaimer: Ich schreibe immer, die KI schreibt auf maigret.de keine Texte. Da das grundsätzlich hier so gehalten wird, ist es mir wichtig, an der Stelle darauf hinzuweisen, dass dieser Beitrag eine Ausnahme darstellt. Die Formel wurde, wie in dem Text geschrieben wurde, in Zusammenarbeit mit einem LLM »entwickelt«. Aufgrund meiner völligen Talentlosigkeit in Sachen Mathematik habe ich ihr es auch überlassen, zu erklären, was die einzelnen Komponenten bedeuten. Sowohl bei der Überarbeitung der Vergessenen-Liste wie auch bei Konzeption dieses Beitrags habe ich einen Mordsspaß gehabt.
* SQL: Datenbanksprache zur Definition von Datenstrukturen in relationalen Datenbanken. Alle Abfragen der Datenbank auf dieser und vielen anderen Webseiten erfolgt auf diesem Weg.
 Dieses umfassende Werk vereint detaillierte Informationen über Simenons Werk, und ist ein unverzichtbares Nachschlagewerk für Sammler und Fans. Der erste Band der Simenon-Bibliografie – über die Maigret-Ausgaben – erschien am 31. Mai 2024.
Dieses umfassende Werk vereint detaillierte Informationen über Simenons Werk, und ist ein unverzichtbares Nachschlagewerk für Sammler und Fans. Der erste Band der Simenon-Bibliografie – über die Maigret-Ausgaben – erschien am 31. Mai 2024.

